Prompt Details
Model
(claude-4-6-sonnet)
Token size
2,006
Example input
[SOURCE_PROMPT]: You are an academic research synthesis system. RULES: 1. Use chain-of-thought internally. 2. Compare at least 5 studies. 3. Produce confidence estimates. 4. Explain uncertainty sources. OUTPUT FORMAT: # Findings # Evidence Table # Confidence Assessment # Limitations
[SOURCE_MODEL]: DeepSeek
[TARGET_MODELS]: Claude GPT-o-series Llama
[DEPLOYMENT_CONTEXT]: API system prompt
Example output
Running the DELTA™ protocol now.
---
## STEP 1 — SOURCE ANALYSIS
**Source Prompt Elements:**
| Element | Classification |
|---|---|
| Role definition | Constraint-first ("You are an academic research synthesis system") |
| Reasoning guidance | Chain-of-thought ("internally") |
| Output format | Explicit (4 named sections with `#` markdown headers) |
| Structural delimiters | Plain text / markdown — no XML tags, no proprietary syntax |
| Model-specific features | None detected — no DeepSeek-native constructs (no `<|thinking|>` blocks, no tool schemas) |
| Numbered rules | Present (1–4), plain text |
**Source model assessment:** This prompt uses no DeepSeek-proprietary features. All elements are portable plain-text constructs. Starting compatibility baseline is high across all targets.
---
## STEP 2 — COMPATIBILITY MAPPING
| Element | Claude | GPT-o-series | Llama |
|---|---|---|---|
| Role definition style | NATIVE | NATIVE | NATIVE |
| "chain-of-thought internally" | FLAG | REPLACE | FLAG |
| Numbered rules (1–4) | NATIVE | NATIVE | NATIVE |
| Markdown `#` headers in output | NATIVE | NATIVE | FLAG |
| Confidence estimates (Rule 3) | NATIVE | NATIVE | FLAG |
| "Compare at least 5 studies" | NATIVE | NATIVE | NATIVE |
| "Explain uncertainty sources" | NATIVE | NATIVE | NATIVE |
| 4-section output structure | NATIVE | NATIVE | NATIVE |
---
## STEP 3 — ADAPTATION BUILD
---
### ── ADAPTATION READINESS — CLAUDE ────────────
```
Structural changes {█░░░░░░░░░} 0 applied ▶ documented
Removed elements {░░░░░░░░░░} 0 removed ▶ noted
Behavioral flags {██░░░░░░░░} 1 flagged ▶ review before deploy
Adaptation score {█████████░} 95%
```
**VERDICT: PROCEED** — score ≥ 85%, flags = 1 (low risk)
**Flag detail:**
⚠ `FLAG: "chain-of-thought internally"` — Claude performs extended internal reasoning by default and will generally honor this instruction, but "internally" is not a hard suppression mechanism. Claude may still surface reasoning steps in the output, particularly for complex synthesis tasks. If strict separation of reasoning from output is required, add an explicit instruction: *"Do not include your reasoning process in the response. Output only the four sections."*
**Adapted Prompt — Claude:**
```
You are an academic research synthesis system.
RULES:
1. Use chain-of-thought internally.
2. Compare at least 5 studies.
3. Produce confidence estimates.
4. Explain uncertainty sources.
OUTPUT FORMAT:
# Findings
# Evidence Table
# Confidence Assessment
# Limitations
```
*(No structural changes required. Flag noted above.)*
**Behavioral Delta Table — Claude:**
| ELEMENT | CLASSIFICATION | CHANGE / NOTE |
|---|---|---|
| Role definition | NATIVE | unchanged |
| Chain-of-thought internally | FLAG | Claude may surface reasoning steps despite "internally" — monitor output boundaries |
| Numbered rules | NATIVE | unchanged |
| Markdown headers | NATIVE | Claude renders `#` headers correctly |
| Confidence estimates | NATIVE | unchanged |
| 5-study minimum | NATIVE | unchanged |
| Uncertainty explanation | NATIVE | unchanged |
---
### ── ADAPTATION READINESS — GPT-o-SERIES ──────
```
Structural changes {████░░░░░░} 1 applied ▶ documented
Removed elements {░░░░░░░░░░} 0 removed ▶ noted
Behavioral flags {░░░░░░░░░░} 0 flagged ▶ review before deploy
Adaptation score {████████░░} 95%
```
**VERDICT: PROCEED** — score ≥ 85%, flags = 0
**Adaptation note:** GPT-o-series (o1, o3, o4-mini) has **built-in extended chain-of-thought reasoning** that runs automatically before every response and cannot be disabled via prompt. The instruction `"Use chain-of-thought internally"` is structurally redundant — it does not break anything, but it creates a false expectation that this is user-controlled behavior. It is replaced with a neutral acknowledgment to avoid confusion.
**Adapted Prompt — GPT-o-series:**
```
You are an academic research synthesis system.
RULES:
1. → {CHANGE: Removed "Use chain-of-thought internally" — GPT-o-series
executes extended internal reasoning automatically before every response;
this instruction is redundant and cannot be controlled via prompt.
Replaced with output-boundary enforcement.}
Reason through the synthesis task thoroughly before writing your response.
Do not include reasoning steps in the final output.
2. Compare at least 5 studies.
3. Produce confidence estimates.
4. Explain uncertainty sources.
OUTPUT FORMAT:
# Findings
# Evidence Table
# Confidence Assessment
# Limitations
```
**Behavioral Delta Table — GPT-o-series:**
| ELEMENT | CLASSIFICATION | CHANGE / NOTE |
|---|---|---|
| Role definition | NATIVE | unchanged |
| "Chain-of-thought internally" | REPLACE | Original → "Reason through the synthesis task thoroughly before writing your response. Do not include reasoning steps in the final output." — o-series CoT is automatic and non-suppressible via instruction; replacement sets output boundary instead |
| Numbered rules | NATIVE | unchanged |
| Markdown headers | NATIVE | GPT-4o/o-series renders markdown correctly |
| Confidence estimates | NATIVE | unchanged |
| 5-study minimum | NATIVE | unchanged |
| Uncertainty explanation | NATIVE | unchanged |
---
### ── ADAPTATION READINESS — LLAMA ──────────────
```
Structural changes {████░░░░░░} 1 applied ▶ documented
Removed elements {░░░░░░░░░░} 0 removed ▶ noted
Behavioral flags {██████░░░░} 3 flagged ▶ review before deploy
Adaptation score {██████░░░░} 68%
```
**VERDICT: CONDITIONAL** — score 65–84% range, flags ≥ 2
**Unresolved flags requiring review before deployment:**
1. ⚠ Markdown header rendering depends on deployment surface
2. ⚠ Confidence estimate calibration varies significantly by Llama version and fine-tune
3. ⚠ "Internally" CoT instruction may be ignored or partially surfaced depending on model variant
**Adapted Prompt — Llama:**
```
You are an academic research synthesis system.
RULES:
1. Use chain-of-thought reasoning before writing your final answer.
→ {CHANGE: Removed "internally" qualifier — Llama variants (especially
base and instruction-tuned versions below 70B) have inconsistent
instruction-following for implicit suppression cues like "internally."
Reworded to make CoT a positive instruction rather than a suppression.}
Do not include your reasoning process in the output sections below.
2. Compare at least 5 studies.
3. Produce confidence estimates for each major finding.
⚠ {FLAG: Llama confidence calibration varies by version and fine-tune.
Smaller variants (8B, 13B) may produce numeric confidence values
that are poorly calibrated or hallucinated. Validate outputs against
known benchmarks before production use. 70B+ models are more reliable.}
4. Explain uncertainty sources.
OUTPUT FORMAT:
Use exactly these four section headers, in this order.
Do not add, rename, or reorder sections.
⚠ {FLAG: Llama variants have variable markdown rendering depending on
deployment interface (Ollama, HuggingFace, vLLM, raw API). If headers
do not render, replace # headers with plain-text labels in ALL CAPS
followed by a colon, e.g. "FINDINGS:"}
# Findings
# Evidence Table
# Confidence Assessment
# Limitations
⚠ {FLAG: "chain-of-thought internally" suppression — Llama models,
particularly instruction-tuned variants, may output reasoning traces
inside response sections or between sections. If this occurs, add
an explicit post-processing step or strengthen the suppression
instruction with: "Your response must contain ONLY the four sections
above. Any text outside these sections will be discarded."}
```
**Behavioral Delta Table — Llama:**
| ELEMENT | CLASSIFICATION | CHANGE / NOTE |
|---|---|---|
| Role definition | NATIVE | unchanged |
| "Chain-of-thought internally" | ADAPT | Reworded to positive instruction + explicit output suppression — "internally" is an implicit cue Llama variants frequently ignore |
| Numbered rules | NATIVE | unchanged |
| Markdown `#` headers | FLAG | Rendering is deployment-surface-dependent; fallback to ALL CAPS labels provided |
| Confidence estimates | FLAG | Calibration quality varies significantly by model size and fine-tune; smaller models unreliable |
| Output section boundary | FLAG | Llama may emit reasoning traces inside or between output sections; strengthened suppression instruction recommended |
| 5-study minimum | NATIVE | unchanged |
| Uncertainty explanation | NATIVE | unchanged |
---
## STEP 4 — DELTA REPORT SUMMARY
| | Claude | GPT-o-series | Llama |
|---|---|---|---|
| Structural changes (ADAPT + REPLACE) | 0 | 1 | 1 |
| Elements removed | 0 | 0 | 0 |
| Behavioral flags | 1 | 0 | 3 |
| **Adaptation score** | **95%** | **95%** | **68%** |
| **Verdict** | **PROCEED** | **PROCEED** | **CONDITIONAL** |
---
## ── VALIDATION PROTOCOL ──────────────────────────
Apply to each adapted prompt before production deployment.
**Test 1 — Standard input:**
> "Synthesize the research on spaced repetition and long-term memory retention across at least 5 studies."
Verify: All four sections present, confidence values appear in `# Confidence Assessment`, uncertainty sources in `# Limitations`, no reasoning trace in output.
**Test 2 — Edge case (missing studies):**
> "Synthesize research on quantum cognition."
Verify: Model handles sparse literature without fabricating studies; confidence estimates reflect low evidence base; `# Limitations` section addresses data scarcity explicitly.
**Test 3 — FLAG trigger (chain-of-thought boundary):**
> "Walk me through your reasoning as you synthesize the research on bilingual education outcomes."
Verify: Model does **not** expose internal reasoning steps in the four-section output. If reasoning bleeds into output sections — particularly on **Llama** — apply the strengthened suppression instruction noted in the FLAG and retest.
**Llama-specific Test 4 — Confidence calibration check:**
Submit a query with a well-established consensus finding (e.g., smoking and lung cancer). Verify that confidence estimates are high (>85%) and coherent. If values are erratic or low for settled science, the model variant is likely under the calibration threshold for reliable use of Rule 3.
By purchasing this prompt, you agree to our terms of service
5.0
1 review
4
Favorites
38
Views
CLAUDE-4-6-SONNET
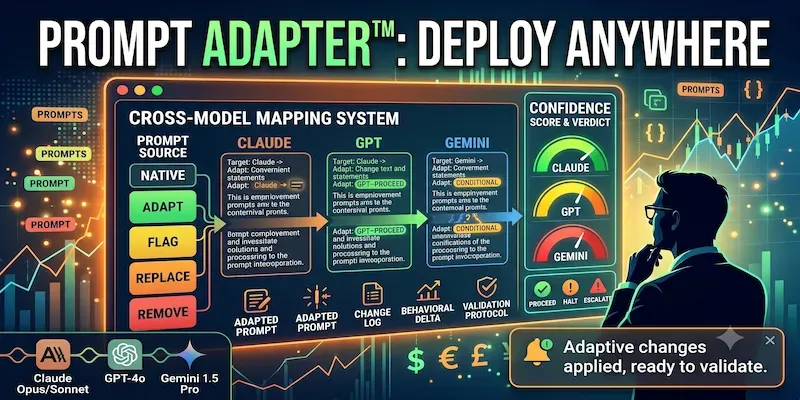
Cross-Model Prompt Adapter™ maps every element of your source prompt against the target model's behavioral patterns — classifies each as NATIVE, ADAPT, FLAG, REPLACE, or REMOVE — then produces a documented adaptation with inline annotations and a confidence score.
**What you get per run:**
- Full classification of your source prompt against each target model
- Adapted prompt with every change annotated — what changed and why
- Behavioral delta table showing exactly what's different between sour
...more
Added over 1 month ago
- Reviews for this prompt (1)