Prompt Details
Model
(claude-4-7-opus)
Token size
2,127
Example input
[PROBLEM_STATEMENT]: "Email FRT in EMEA doubled in September"
[CONTEXT_SCOPE]: "EMEA email queue; new triage bot deployed Aug 28"
[DATA_EVIDENCE]: "Queue logs Sep 1–16; bot transcripts; staffing roster"
[RCA_METHOD]: "Fishbone, 5 Whys, A/B rollback test"
[ACTION_PLAN_CRITERIA]: "FRT ≤2h; routing fix; agent retrain; QA sampling"
Example output
# EMEA Email FRT Doubled in September — RCA Report
**Mode:** standard | All 8 protocol sections + mandatory Sections 9–10
---
## SECTION 1 — Problem Brief
- **Issue (what/when):** Email First Response Time (FRT) in EMEA doubled during September. {E}
- **Where:** EMEA email queue; new triage bot deployed August 28. {E}
- **Context:**
- Triage bot was deployed Aug 28, four days before the September FRT window began. {E}
- Queue logs are available for Sep 1–16 only; second half of September not in scope. {E}
- Staffing roster is available but headcount changes, shift coverage, and PTO patterns relative to August baseline are not stated. {G}
- August baseline FRT value, on which the "doubled" claim rests, is not provided in inputs. {G}
- No information on bot configuration changes, model version, or routing rule deployments after Aug 28. {G}
- **Impact:** SLA breach risk on email channel; potential CSAT degradation and escalation volume increase. Magnitude unquantified. {G}
- **Success criteria:** {E}
- FRT ≤ 2 hours
- Routing fix implemented
- Agent retraining executed
- QA sampling regime in place
---
## SECTION 2 — Evidence Log
**Internal data confirmed in DATA_EVIDENCE:**
- Queue logs → Sep 1–16 timestamps → enables FRT distribution, arrival rate (λ), and service time analysis per ticket. {E}
- Bot transcripts → triage decisions per ticket → enables routing-accuracy and misrouting-rate computation. {E}
- Staffing roster → agent shifts/availability → enables capacity (μ) and utilization (ρ = λ/μ) computation. {E}
**Internal data NOT yet confirmed (gaps):**
- August baseline FRT, arrival rate, and staffing → owner: workforce management / ops analytics. {G}
- Bot configuration version history (Aug 28 deploy + any subsequent changes) → owner: bot platform team. {G}
- Routing rule changes in ticketing system in Aug–Sep window → owner: ticketing system admin. {G}
- Backlog state at Sep 1 vs Aug 1 (carried-over open tickets) → owner: ops analytics. {G}
- Agent-level handle time and login adherence in September → owner: workforce management. {G}
- Sep 17–30 queue logs → owner: ticketing system admin. {G}
- CSAT and escalation rates for Sep — to confirm impact severity. {G}
**Computation/validation methods:**
- Little's Law: L = λW, where L = tickets in system, λ = arrival rate, W = average time in system. Useful to test whether FRT growth is driven by λ↑, μ↓, or both. {Analysis}
- Routing-accuracy test: from bot transcripts, compute misroute rate = (tickets reassigned after bot triage) / (total bot-triaged tickets). {Analysis}
- Utilization check: ρ = λ/μ. As ρ approaches 1, queue time grows non-linearly — small capacity drops produce large FRT spikes. {Analysis}
- Sanity check: compare Sep 1–16 FRT distribution against August baseline FRT distribution; without August data this cannot be executed. {G}
**External references:** none — standard mode does not run external citation pass.
---
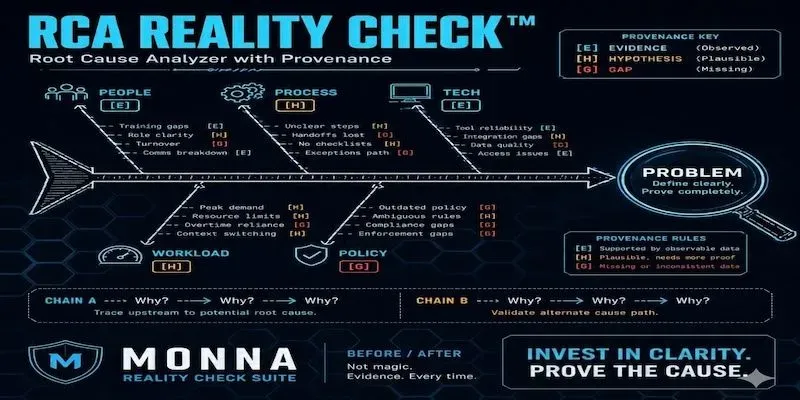
## SECTION 3 — Cause Map (Fishbone + Two 5-Whys Chains)
### ASCII Fishbone
```
PEOPLE PROCESS TECHNOLOGY
| | |
- agent unfamiliar - new triage SOP - triage bot v.X
with bot output {H} not aligned to bot {H} misclassifies {H}
- shift coverage - escalation path - routing rules
gap EMEA hours {G} broken by bot {H} not updated {H}
- retrain not yet - QA sampling not - bot/ticketing
done {E} catching misroutes {H} integration lag {H}
| | |
_______|________________________|________________________|________
|
EMEA Email FRT 2x
________________________________|________________________________
| | |
| | |
WORKLOAD POLICY/CONSTRAINTS
| |
- arrival rate ↑ Sep - SLA target ≤2h
vs Aug {G} unchanged {E}
- backlog carry-over - no rollback policy
from Aug {G} for bot deploys {H}
- ticket complexity - no staffing buffer
mix shift {G} for new-tool ramp {H}
- seasonal volume - escalation policy
spike {H} not bot-aware {H}
```
**Branch summary:**
- PEOPLE: 3 candidates — 1 {E}, 1 {H}, 1 {G}
- PROCESS: 3 candidates — all {H}
- TECHNOLOGY: 3 candidates — all {H}, all linked to Aug 28 bot deploy
- WORKLOAD: 4 candidates — 1 {H}, 3 {G} (volume claims unsupported by inputs)
- POLICY/CONSTRAINTS: 4 candidates — 1 {E}, 3 {H}
### 5-Whys — Chain A: Technical/Process root
Focus: triage bot misrouting tickets.
1. **Why did Sep FRT double?** Tickets are sitting longer before first agent touch. {H — pending FRT decomposition from queue logs}
2. **Why are tickets sitting longer?** A subset is being routed to wrong queues by the bot, then reassigned, restarting the wait clock. {H — testable from bot transcripts + reassignment logs}
3. **Why is the bot misrouting?** Bot classification rules were not validated against the live EMEA ticket distribution before Aug 28 deploy. {H}
4. **Why was validation skipped?** No pre-deployment shadow/dry-run gate exists for triage bot changes. {H}
5. **Why is no shadow gate required?** The change-management policy for ML/automation deploys does not mandate parallel-run validation. {H — SYSTEMIC: missing control on automation deployment}
**Termination:** Missing change-control gate for automation deploys.
### 5-Whys — Chain B: Capacity/Timing root
Focus: capacity buffer for new-tool ramp.
1. **Why did Sep FRT double?** Average time in system W increased; per Little's Law (L = λW) this means either L grew or λ outpaced effective service rate μ. {Analysis}
2. **Why did effective service rate drop?** Agents are spending additional time correcting bot triage outcomes, reducing throughput per agent-hour. {H — testable from handle-time delta vs August baseline {G}}
3. **Why was this absorption capacity not planned?** Staffing for September was set assuming the bot would reduce, not add, agent workload. {H}
4. **Why was that assumption not stress-tested?** No staffing buffer model exists for the ramp period of new automation tools. {H}
5. **Why is no ramp buffer required?** Workforce-planning policy treats automation deploys as immediate net-positive, with no provisional buffer or trigger to add capacity if early metrics regress. {H — SYSTEMIC: missing feedback loop between deploy outcomes and staffing}
**Termination:** Missing feedback loop between automation outcomes and capacity planning.
**Independence check:** Chain A terminates at a missing pre-deploy control; Chain B terminates at a missing post-deploy capacity feedback loop. Distinct systemic roots. ✓
---
## SECTION 4 — Validated Root Causes
### RC-1: Triage bot misclassification driving rework loops
- **Status:** Likely {H+E} — bot transcripts {E} exist and can confirm; misroute rate not yet computed.
- **Evidence basis:** Aug 28 bot deploy {E} immediately precedes Sep FRT increase {E}; bot transcripts available {E}.
- **Targeted test:** A/B rollback — disable bot for 25% of incoming EMEA email for 5 business days; compare FRT distributions. Success metric: rollback cohort FRT ≥ 30% lower than bot-on cohort, with p-value or effect-size threshold defined by analytics owner.
- **Confidence:** MEDIUM — auto-downgrade applied because August baseline {G} and routing rule history {G} are missing.
### RC-2: Missing pre-deploy validation gate for automation
- **Status:** Unconfirmed {H}
- **Evidence basis:** Inferred from absence of shadow-run evidence in inputs; no validation artifacts referenced in DATA_EVIDENCE.
- **Targeted test:** Document review of change-management policy for automation deploys; confirm presence/absence of shadow-mode requirement.
- **Confidence:** LOW — fully {H}, requires policy artifact to upgrade.
### RC-3: Capacity not buffered for bot ramp period
- **Status:** Unconfirmed {H or G}
- **Evidence basis:** Staffing roster {E} is available but the September vs August delta is not stated; bot impact on per-agent handle time is uncomputed.
- **Targeted test:** Compute Sep handle-time per agent vs August baseline; recompute ρ = λ/μ for both periods. Success metric: if Sep ρ > August ρ by ≥10 points, capacity erosion is confirmed.
- **Confidence:** LOW — auto-downgrade applied, August baseline {G}.
### RC-4: Agent unfamiliarity with bot output (training gap)
- **Status:** Likely {H+E} — retrain not yet done {E}.
- **Evidence basis:** Retraining is named in ACTION_PLAN_CRITERIA as a required action, implying acknowledged gap. {E inferred from criteria}
- **Targeted test:** Sample agent ticket-handling time on bot-triaged vs non-bot-triaged tickets; if bot-triaged tickets take longer in Sep but not in pre-Aug-28 sample, training gap is confirmed.
- **Confidence:** LOW — auto-downgrade applied, requires baseline {G}.
---
## SECTION 5 — Countermeasure Plan
### A. Immediate mitigations (0–5 days)
| ID | Action | Root cause | Owner | Due |
|---|---|---|---|---|
| A1 | Run A/B rollback test on 25% EMEA email cohort | RC-1 {H} | EMEA ops lead {G} | D+2 {H} |
| A2 | Compute misroute rate from bot transcripts (Sep 1–16) | RC-1 {E data} | Analytics {G} | D+3 {H} |
| A3 | Pull August FRT, λ, and staffing baseline | RC-3, all {G} | Workforce management {G} | D+2 {H} |
| A4 | Spot-retrain agents on bot output interpretation (single 1h session) | RC-4 {H+E} | Training lead {G} | D+5 {E from criteria} |
### B. Corrective actions (5–14 days)
| ID | Action | Root cause | Owner | Due |
|---|---|---|---|---|
| B1 | Implement routing-rule fix based on misroute analysis (A2 output) | RC-1 {H} | Bot platform team {G} | D+10 {E from criteria: "routing fix"} |
| B2 | Stand up QA sampling regime: ≥5% of bot-triaged tickets reviewed | RC-1, RC-4 | QA lead {G} | D+10 {E from criteria: "QA sampling"} |
| B3 | Adjust EMEA staffing if A3 + RC-3 test confirms capacity erosion | RC-3 {H} | Workforce management {G} | D+12 {H} |
| B4 | Full agent retraining cohort on bot integration | RC-4 {H+E} | Training lead {G} | D+14 {E from criteria: "agent retrain"} |
### C. Preventive controls (14+ days, ongoing)
| ID | Action | Root cause | Owner | Due |
|---|---|---|---|---|
| C1 | Add mandatory shadow-mode gate for automation deploys (≥7 days parallel run) | RC-2 {H — Chain A systemic root} | Change management owner {G} | D+30 {H} |
| C2 | Add automation-ramp staffing buffer policy (provisional +X% capacity for first 30 days post-deploy) | RC-3 {H — Chain B systemic root} | Workforce planning lead {G} | D+30 {H} |
| C3 | Establish post-deploy metric review at D+7 / D+14 with rollback trigger thresholds | RC-2, RC-3 {H} | Ops director {G} | D+30 {H} |
---
## SECTION 6 — Control Plan & KPIs
| Metric | Target/Guard | Where measured | Cadence | Owner | Verification |
|---|---|---|---|---|---|
| Email FRT (primary outcome) | ≤ 2 hours {E} | Ticketing system, EMEA queue | Daily | EMEA ops lead {G} | Compare 7-day rolling avg against target |
| Bot misroute rate (leading indicator) | ≤ 5% {H — proposed} | Bot transcripts + reassignment log | Daily | QA lead {G} | Sample audit weekly |
| Agent utilization ρ (capacity) | ≤ 0.85 {H — proposed, queueing-theory guard against non-linear queue blow-up} | Staffing roster + queue logs | Weekly | Workforce management {G} | ρ = λ/μ recomputed weekly |
| QA sampling coverage (quality) | ≥ 5% of bot-triaged tickets {H — proposed} | QA tool | Weekly | QA lead {G} | Audit log of sampled tickets |
| Reassignment rate (quality) | ≤ baseline + 2pp {H — baseline missing {G}} | Ticketing reassignment events | Daily | Analytics {G} | Trend chart |
---
## SECTION 7 — Risks, Assumptions & Evidence Gaps
**Risks:**
- {H} September volume spike from external factor (e.g., product release, outage, marketing event) could mask any improvement from B1–B4.
- {H} Sep 17–30 conditions may differ materially from Sep 1–16, making test conclusions from the 16-day window non-generalizable.
- {H} Rollback test cohort selection bias if 25% sample is not representative across EMEA sub-regions or ticket categories.
- {H} Agent retraining (A4, B4) without parallel routing fix (B1) could mask which lever moved FRT.
**Assumptions:**
- {H} Bot deploy on Aug 28 is the dominant change in the Aug→Sep window. If other concurrent changes exist (routing rules, staffing model, ticket categorization), causal attribution weakens.
- {H} Queue logs Sep 1–16 represent typical September behavior.
- {H} Staffing roster reflects actual worked hours, not just scheduled hours.
- {H} EMEA email queue is operationally isolated from other channels and regions for the test.
**Evidence gaps (rank-ordered, close within 72 hours):**
1. {G} August FRT baseline + arrival rate + staffing — without this, "doubled" cannot be quantified or decomposed.
2. {G} Bot configuration / version history since Aug 28 — needed to rule out post-deploy drift.
3. {G} Routing rule changes in ticketing system Aug–Sep — needed to isolate bot effect.
4. {G} Sep 17–30 queue logs — needed to confirm trend continuity.
5. {G} Backlog carry-over state (Aug 31 → Sep 1 open tickets) — needed for L term in Little's Law.
6. {G} CSAT and escalation rates for Sep — needed to size impact.
---
## SECTION 8 — Executive Summary
EMEA email FRT doubled in September {E}, immediately following the Aug 28 deployment of a new triage bot {E}. The most likely mechanism is bot misclassification driving reassignment-and-rework loops that reset the first-response clock {H}, compounded by capacity not having been buffered for the ramp period of a new automation tool {H}. Both pathways point to systemic gaps: no pre-deploy validation gate for automation, and no post-deploy feedback loop between deploy outcomes and staffing.
**This week:** run a 25% A/B rollback of the bot to confirm causal attribution (A1); compute misroute rate from existing bot transcripts (A2); pull the missing August baseline so "doubled" can be quantified and decomposed (A3); and run a single targeted retrain session on bot output interpretation (A4).
**Definition of "good":** FRT ≤ 2 hours {E}, routing fix shipped {E}, agent retraining completed {E}, and QA sampling regime running {E}.
**Confidence note:** Six of the most consequential evidence gaps are open {G}. Until the August baseline lands, all root-cause confidence levels are MEDIUM or LOW.
---
## SECTION 9 — Refused Inferences
- **Item:** "Bot deploy caused the FRT doubling."
**Why refused:** Temporal coincidence is established {E} but no decomposition (misroute rate, handle-time delta, λ change) has been computed. Multiple alternative or compounding causes remain live.
**What would change my mind:** Misroute rate from A2 + August baseline from A3, showing FRT growth concentrated in bot-triaged ticket cohort.
- **Item:** "Volume spike caused the FRT doubling."
**Why refused:** No arrival-rate data for August or for September comparison is in inputs.
**What would change my mind:** August λ vs September λ; if September λ is materially higher and ρ approaches 1, capacity-driven explanation gains weight independent of bot effect.
- **Item:** "Agents are the bottleneck (skill/training)."
**Why refused:** Retraining is named in success criteria {E}, but no per-agent handle-time or skill-distribution data has been examined.
**What would change my mind:** Sep handle-time per agent on bot-triaged vs non-bot-triaged tickets, controlled for ticket complexity.
- **Item:** "FRT doubled across all of September."
**Why refused:** Queue logs cover Sep 1–16 only {E}. Sep 17–30 is {G}.
**What would change my mind:** Sep 17–30 queue logs.
- **Item:** Adding a sixth fishbone branch (e.g., "External" or "Customer behavior").
**Why refused:** Protocol fixes the 5-branch fishbone. External seasonal volume is captured under WORKLOAD; customer behavior changes are not in inputs.
**What would change my mind:** Not applicable — protocol constraint, not evidence-based.
---
## SECTION 10 — Method & Provenance Note
- **RCA flow followed:**
1. Problem framing (Section 1) against PROBLEM_STATEMENT and CONTEXT_SCOPE
2. Evidence inventory (Section 2) against DATA_EVIDENCE
3. Fishbone — 5 fixed branches (Section 3)
4. 5 Whys — two independent chains terminating at systemic roots (Section 3)
5. Root-cause validation with targeted A/B rollback test (Section 4) per RCA_METHOD
6. Three-horizon countermeasure plan mapped to ACTION_PLAN_CRITERIA (Section 5)
7. Control plan with primary, leading, capacity, and quality KPIs (Section 6)
8. Risk + assumption + gap surfacing (Section 7)
9. Refused-inference audit trail (Section 9)
- **Provenance trail:** {E} ≈ 14 | {H} ≈ 38 | {G} ≈ 14 | {Cited} = 0 | {Analysis} = 4
- **Mode:** standard (no external citations)
- **Limitations:** Without August baseline, the "doubled" claim cannot be quantified or decomposed into λ, μ, or W components. Without bot configuration history and concurrent routing-rule changes, causal attribution of FRT growth specifically to the Aug 28 bot deploy remains {H}, not {E}. Sep 17–30 conditions are unobserved; conclusions generalize from the first half of the month only. All staffing and ownership assignments in Sections 5 and 6 are role-based placeholders {G} pending org confirmation.
By purchasing this prompt, you agree to our terms of service
25
Views
CLAUDE-4-7-OPUS
When something breaks at work — support response time doubles, latency spikes, yield drops — most RCA prompts will confidently invent a clean causal story. This one won't.
✅ Produces a complete 8-section RCA report (problem brief → executive summary)
✅ ASCII fishbone with 5 fixed branches + two parallel 5-Whys chains
✅ Every claim tagged Evidence / Hypothesis / Gap — no silent guessing
✅ Refused-inferences section makes the "I don't know yet" explicit
✅ Three depth modes: 2-min triage, standard
...more
Added 4 weeks ago