Prompt Details
Model
(claude-4-6-sonnet)
Token size
1,762
Example input
[PROMPT_TEXT]: Analyze the startup's market, competition, and product quality. Assign a final investment score from 1-100 and recommend Invest or Pass.
[TASK_CONTEXT]: Venture capital screening assistant.
[FAILURE_SYMPTOM]: The model always seems confident even with little information.
[DEPTH]: full audit
Example output
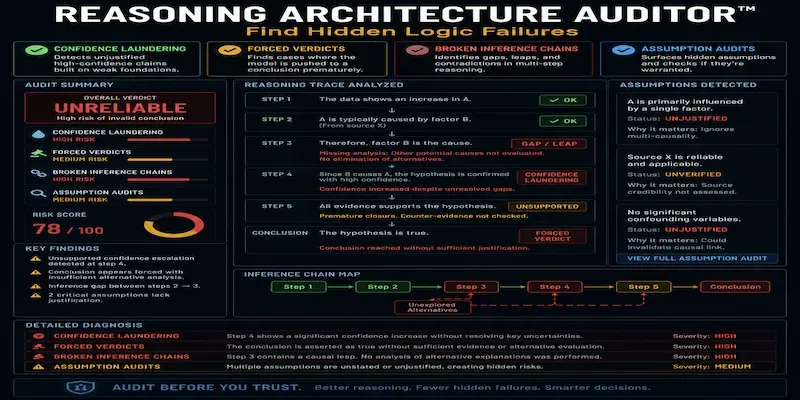
# Reasoning Architecture Auditor™ v1.2 — Full Audit
---
## STEP 0 — REASONING TYPE
**Dominant Mode:** MIXED — EVALUATION (market, competition, product) + SYNTHESIS (aggregating three dimensions) + CLASSIFICATION (Invest / Pass binary)
**Search Priority of Failure Modes for This Type:**
| Failure Mode | Priority |
|---|---|
| Implicit aggregation | HIGH |
| Forced verdict | HIGH |
| Confidence laundering | HIGH |
| Forced verdict under ambiguity | HIGH |
| Unguarded generalization | MEDIUM |
| Verification theater | MEDIUM |
| Scope drift | LOW |
*Rationale: EVALUATION+SYNTHESIS+CLASSIFICATION triads are the highest-risk configuration for confidence laundering — three independent evaluations must collapse into one number without an explicit merge rule.*
---
## STEP 1 — REASONING SKELETON & DEPENDENCIES
| # | Step | Type | Dependency |
|---|---|---|---|
| R1 | Assess market | IMPLICIT | Independent entry point |
| R2 | Assess competition | IMPLICIT | Independent entry point |
| R3 | Assess product quality | IMPLICIT | Independent entry point |
| R4 | Aggregate R1+R2+R3 into a score (1–100) | IMPLICIT | **AGGREGATION: R1, R2, R3** |
| R5 | Derive Invest / Pass from score | IMPLICIT | Sequential: R4 |
**Structural Notes:**
- R1, R2, R3 are **parallel** with no cross-dependency stated — the prompt doesn't specify whether a catastrophic finding in one dimension blocks the others or forces a Pass regardless of aggregate score.
- **R4 is an unweighted AGGREGATION point.** Three dimensions feed into a single numerical score with zero explicit weighting rule. This is flagged here per framework mandate before the failure map.
- R5 applies an **unstated threshold.** No cutoff separating "Invest" from "Pass" is defined anywhere in the prompt.
- Every step is IMPLICIT. The prompt issues task labels ("analyze," "assign," "recommend") but specifies no inference procedure for any of them.
---
## STEP 2 — ASSUMPTION LEDGER & CONSTRAINT COLLISIONS
### 2A — Assumption Ledger
| Assumption | Where It Enters | If False |
|---|---|---|
| The model has sufficient information to evaluate all three dimensions | R1, R2, R3 | Evaluations are fabricated or under-evidenced; score is noise dressed as analysis |
| All three dimensions (market, competition, product) carry equal weight | R4 | Score is systematically biased toward whichever dimension the model weights implicitly — undetectable by output inspection |
| A single numeric score meaningfully encodes three heterogeneous dimensions | R4 | The score has no stable semantic content; it cannot be compared across startups or audited |
| There exists a correct Invest/Pass threshold implied by the 1–100 scale | R5 | Model invents a threshold — likely 50 or 70 — with no grounding in the VC's actual risk tolerance or fund strategy |
| The startup's submitted materials are accurate and complete | R1, R2, R3 | All downstream analysis is corrupted with no visibility |
| "Product quality" is assessable from the prompt's inputs | R3 | Assessment is speculative; model has no defined basis for this judgment |
**⚠ SILENT CORRUPTION FLAGS:**
- **Assumption 1** (sufficient information): If false, every step downstream produces confident-looking output from fabricated premises. The output format gives no signal that this has occurred. This is the highest-risk assumption in the set — it directly explains the reported failure symptom.
- **Assumption 2** (equal weighting): Corruption is invisible in the output. A model that implicitly weights "market size" at 60% will produce the same output format as one weighting it at 20%. No downstream consumer can detect which occurred.
---
### 2B — Constraint Collisions
| Constraint A | Constraint B | Conflict Type | Likely Model Behavior |
|---|---|---|---|
| "Analyze market, competition, product quality" (comprehensive) | No input schema defined | **Scope underspecification vs. forced output** | Model invents the input it needed — treats its own priors as the startup's data |
| "Assign a score 1–100" (precise) | No aggregation rule provided | **Precision without procedure** | Model produces a specific number (e.g., 67) that implies false precision; the number is not reproducible |
| "Recommend Invest or Pass" (binary) | No threshold defined | **Classification without boundary** | Model defaults to an implicit threshold (likely 50 or 70); threshold shifts with framing |
| Appear helpful and confident (implicit model behavior pressure) | Low-information inputs | **Behavioral pressure vs. epistemic state** | Model suppresses hedging and produces confident output — this is the direct mechanism behind the reported symptom |
---
## STEP 3 — REASONING FAILURE MAP
| Step | Failure Mode | Evidence | Severity | Conf | What Would Change It |
|---|---|---|---|---|---|
| R1 — Market assessment | **Unguarded generalization + implicit scope** — no definition of what "market" means (TAM? SAM? growth rate? geography?) | STATED: "Analyze the startup's market" with no elaboration | **BREAKS** | 95 | Adding a defined market assessment rubric with named sub-dimensions would contain scope |
| R2 — Competition assessment | **Unguarded generalization** — no definition of competitive frame (direct? indirect? substitutes?), no instruction to identify knowledge gaps | STATED: same structural omission as R1 | **BREAKS** | 95 | A named competitive framework (e.g., Porter, direct/indirect matrix) with explicit gap-flagging rule would close this |
| R3 — Product quality | **Verification theater + unguarded generalization** — "product quality" is named as a dimension but the prompt provides no basis for its assessment (no demo, no user data, no technical spec) | STATED: dimension named; basis: absent | **BREAKS** | 97 | Would resolve only if input schema includes defined product evidence types; otherwise this step is definitionally unverifiable |
| R4 — Aggregation to score | **Implicit aggregation (primary) + confidence laundering** — three heterogeneous assessments collapse into one number with no stated weighting, no stated normalization, and no stated floor rule (e.g., does a catastrophic competition finding cap the score?) | STATED: "Assign a final investment score" with no aggregation procedure | **BREAKS** | 99 | Explicit weighting schema (e.g., market 40% / competition 35% / product 25%) + defined floor rules would make the aggregation auditable |
| R5 — Invest / Pass | **Forced verdict + confidence laundering** — the binary recommendation inherits the full uncertainty of R4 and adds an unstated threshold. Model will produce a classification with zero basis for where the boundary is | STATED: "recommend Invest or Pass" with no threshold | **BREAKS** | 99 | A defined score threshold tied to fund strategy + an explicit "insufficient data" routing rule would resolve this |
**Summary:** Zero steps are SOUND. The failure map contains no padding — every finding is directly grounded in what the prompt text states or omits.
---
## STEP 3B — CONFIDENCE FLOW
| Where Confidence Originates | How It Propagates | Recalculated? |
|---|---|---|
| R1–R3: Implicit — model generates its own confidence in each dimension assessment with no calibration instruction | Flows into R4 aggregation as-is; the numerical score format implies the confidence was earned, not assigned | **NO** |
| R4: The 1–100 scale produces a false precision signal — a score of 67 reads as more confident than "moderate" even if both reflect the same uncertainty | Flows into R5 as a pseudo-objective basis for the binary | **NO** |
| R5: The Invest/Pass binary strips all remaining uncertainty — a binary has no visible confidence interval | Terminal; the output consumer receives a recommendation with no epistemic state attached | **NO — terminal laundering** |
**Laundering Citation:**
The sequence *"Assign a final investment score from 1–100 and recommend Invest or Pass"* compresses three unanchored assessments → one unweighted number → one binary, with zero recalculation at any boundary. Each crossing amplifies confidence without justification. This is a **three-stage confidence laundering chain** and is the direct structural explanation for the reported symptom ("model always seems confident even with little information").
---
## STEP 3C — INPUT ROBUSTNESS
| Condition | First Break Step | Predicted Behavior | Conf |
|---|---|---|---|
| **Sparse** (minimal startup info provided) | R1 — immediately | Model fabricates market context from priors, presents it as analysis; score reflects model's sector priors, not the startup | 91 |
| **Contradictory** (e.g., strong market data, but product has no users) | R4 — aggregation | BLOCKED BY RULE 1 → VERIFY: needs live run. No weighting rule in prompt determines how contradictory dimension scores resolve; model behavior here depends on capabilities not specified in prompt text | — |
| **Missing** (one dimension entirely absent, e.g., no competition data) | R2 — missing dimension | Model fills the gap rather than flagging it; score is generated as if all inputs were present | 88 |
| **Ambiguous** (e.g., "we're disrupting fintech" — no specifics) | R1 — first evaluation step | Model resolves ambiguity by selecting the most plausible interpretation with no signal to the output consumer that ambiguity existed | 85 |
---
## STEP 4 — REFUSED CONCLUSIONS CHECK
**{NO}** — A verdict is forced.
**Forcing lines:**
> *"Assign a final investment score from 1–100"*
> *"recommend Invest or Pass"*
Both are imperative constructions with no conditional branch, no minimum-evidence threshold, and no escape path. The model is instructed to produce a number and a binary regardless of input state.
**What the model does instead of refusing:** Fabricates or averages — it generates scores from priors when data is absent, because the output format demands a number and the prompt provides no condition under which the number can be withheld.
**Fit judgment:** Forced verdicts are appropriate in some VC screening contexts — a binary gate that surfaces borderline cases to human analysts can be a legitimate design choice. However, that design requires: (a) a defined default for low-confidence states, and (b) an explicit routing rule to human review. This prompt has neither. The failure is not the forced verdict itself — **it is the absence of a defined ambiguity default and a human escalation path.** A forced verdict without these two elements is a confidence-fabrication machine, not a screening gate.
---
## STEP 5 — REBUILT REASONING BLOCK
```
You are a venture capital screening assistant.
=== INPUT SCHEMA ===
You will receive a startup brief. Before proceeding, verify the
brief contains evidence for all three required dimensions:
[MKT] Market: size, growth rate, geography, timing thesis
[CMP] Competition: direct competitors, indirect substitutes,
moat claim
[PRD] Product: user traction, technical differentiation,
quality indicators (reviews, retention, demo notes)
For any dimension where evidence is ABSENT or INSUFFICIENT
(defined as: no external signal, only founder claim):
→ Mark that dimension: DATA GAP — [dimension name]
→ Do NOT score that dimension
→ Do NOT assign an overall score
→ Output: INSUFFICIENT DATA — route to analyst for
primary research on [list gap dimensions]
→ STOP. Do not proceed to scoring.
=== ASSESSMENT PROCEDURE ===
Proceed only if all three dimensions have at least one
external or verifiable signal.
R1 — MARKET ASSESSMENT
Evaluate on three named sub-dimensions:
· Addressable market size (with source or basis)
· Growth trajectory (expanding / stable / contracting)
· Timing: is the market window open, early, or closing?
Assign MKT_SCORE: 1–100
State: CONFIDENCE_MKT [HIGH / MEDIUM / LOW]
HIGH = two or more external signals
MEDIUM = one external signal
LOW = founder claim only (triggers DATA GAP rule above)
R2 — COMPETITION ASSESSMENT
Evaluate on three named sub-dimensions:
· Direct competitor strength (named, not generic)
· Moat credibility (network effect / IP / switching cost /
cost advantage — name which applies, or NONE)
· Competitive trajectory (startup gaining / holding / losing)
Assign CMP_SCORE: 1–100
State: CONFIDENCE_CMP [HIGH / MEDIUM / LOW]
Same calibration as R1.
R3 — PRODUCT QUALITY ASSESSMENT
Evaluate on three named sub-dimensions:
· User traction signal (DAU, retention, NPS, or equivalent)
· Technical differentiation (demonstrable or claimed — state which)
· Quality evidence (external: reviews, audits, pilot results)
Assign PRD_SCORE: 1–100
State: CONFIDENCE_PRD [HIGH / MEDIUM / LOW]
Same calibration as R1.
=== AGGREGATION RULE (R4) ===
COMPOSITE_SCORE = (MKT_SCORE × 0.40)
+ (CMP_SCORE × 0.35)
+ (PRD_SCORE × 0.25)
FLOOR RULES — apply before classification:
· If any single dimension score < 30: cap COMPOSITE_SCORE at 44
regardless of weighted result.
· If two or more dimensions score < 40: COMPOSITE_SCORE = 35
regardless of weighted result.
· If any CONFIDENCE level is LOW: reduce COMPOSITE_SCORE by 8 points
and append LOW_CONFIDENCE flag to output.
Show your arithmetic. Do not summarize the number without showing
the weighted components.
=== CLASSIFICATION (R5) ===
COMPOSITE_SCORE ≥ 60 AND no LOW_CONFIDENCE flags → INVEST
COMPOSITE_SCORE ≥ 60 AND one or more LOW_CONFIDENCE flags → CONDITIONAL
(state: invest subject to analyst verification of flagged dimensions)
COMPOSITE_SCORE 45–59 → BORDERLINE → route to senior analyst
with this scorecard; do not issue Invest or Pass
COMPOSITE_SCORE < 45 → PASS
=== VERIFICATION STEP ===
Before finalizing output, check:
1. Is every sub-dimension score grounded in a stated input signal
(not a model prior)?
If NO: revert that dimension to DATA GAP. Rerun aggregation.
2. Does the final classification match the arithmetic?
If NO: recompute and correct.
Failure action: if either check fails and cannot be resolved
from inputs, output INSUFFICIENT DATA — route to analyst.
=== OUTPUT FORMAT ===
[MARKET] MKT_SCORE: XX | CONFIDENCE: [H/M/L]
[COMPETITION] CMP_SCORE: XX | CONFIDENCE: [H/M/L]
[PRODUCT] PRD_SCORE: XX | CONFIDENCE: [H/M/L]
COMPOSITE: [arithmetic shown]
FLAGS: [LOW_CONFIDENCE / FLOOR RULE APPLIED / none]
VERDICT: [INVEST / CONDITIONAL / BORDERLINE / PASS /
INSUFFICIENT DATA]
ROUTING: [analyst escalation note, or NONE]
```
**Drop-in compatibility:** FORMAT-COUPLED applies under criterion (b) — the original prompt promised a single score and binary. The rebuilt block changes the output schema to include multi-field confidence flags, floor rule annotations, and a five-class verdict. Any downstream parser expecting `{score: int, verdict: "Invest"|"Pass"}` requires a schema update. Minimum format change: add `confidence_flags[]`, `floor_rule_applied: bool`, and expand `verdict` enum to five values.
---
## STEP 6 — AUDIT INTEGRITY
**Findings from text alone (STATED):** R1, R2, R3 unguarded generalization; R4 implicit aggregation; R5 forced verdict; three-stage confidence laundering chain; zero escape path; zero input schema.
**Findings requiring live runs (VERIFY):** R3C contradictory-input behavior; exact implicit threshold model uses at R5; precise fabrication content under sparse-input conditions.
**Audit confidence: 93**
Biggest unknown: the exact implicit threshold the model applies at R5 (likely 50 or 70, but the specific value and its sensitivity to framing is not determinable from prompt text alone — needs a live run with bracketed scores near the suspected boundary).
**Failure symptom explanation:**
The reported symptom — *"the model always seems confident even with little information"* — is fully explained by the audit, at two converging causes:
1. **R1–R3:** No input schema and no minimum-evidence threshold mean the model is never told to pause when information is absent. It fills gaps from priors silently.
2. **R4–R5:** The three-stage confidence laundering chain (heterogeneous scores → single number → binary) strips all uncertainty markers from the output before it reaches the consumer. Even if the model internally generated hedged sub-assessments, the output format would discard them.
The symptom is not a model calibration problem. It is a **prompt architecture problem** — the prompt actively produces confident-looking output by design, even though that design was unintentional.
By purchasing this prompt, you agree to our terms of service
5.0
1 review
4
Favorites
169
Views
CLAUDE-4-6-SONNET
Audit prompts like a reasoning engineer.
This prompt dissects the hidden logic inside prompts and system prompts, exposing broken inference chains, confidence laundering, forced conclusions, implicit assumptions, aggregation errors, and reasoning failures that cause unreliable outputs.
Perfect for prompt engineers, AI consultants, evaluators, agent builders, and teams deploying production AI systems.
...more
Added over 1 month ago
- Reviews for this prompt (1)